React key attribute: best practices for performant lists
Looking into how React "key" attribute works, how to use it correctly, how to improve performance of lists with it, and why array index as key is a good idea sometimes
Nadia Makarevich

React “key” attribute is probably one of the most “autopilot” used features in React 😅 Who among us honestly can say that they use it because of “…some valid reasons”, rather than “because eslint rule complained at me”. And I suspect most people when faced with the question “why does React need “key” attribute” will answer something like “errr… we’re supposed to put unique values there so that React can recognise list items, it’s better for performance”. And technically this answer is correct. Sometimes.
But what exactly does it mean “recognise items”? What will happen if I skip the “key” attribute? Will the app blow up? What if I put a random string there? How unique the value should be? Can I just use array’s index values there? What are the implications of those choices? How exactly do any of them impact performance and why?
Let’s investigate together!
How does React key attribute work
First of all, before jumping into coding, let’s figure out the theory: what the “key” attribute is and why React needs it.
In short, if the “key” attribute is present, React uses it as a way to identify an element of the same type among its siblings during re-renders (see the docs: https://reactjs.org/docs/lists-and-keys.html and https://reactjs.org/docs/reconciliation.html#recursing-on-children).In other words, it’s needed only during re-renders and for neighbouring elements of the same type, i.e. flat lists (this is important!).
A simplified algorithm of the process during re-render looks like this:
- first, React will generate the “before” and “after” “snapshots” of the elements
- second, it will try to identify those elements that already existed on the page, so that it can re-use them instead of creating them from scratch
- if the “key” attribute exists, it will assume that items with the same “before” and “after” key are the same
- if the “key” attribute doesn’t exist, it will just use sibling’s indexes as the default “key”
- third, it will:
- get rid of the items that existed in the “before” phase, but don’t exist in the “after” (i.e. unmount them)
- create from scratch items that haven’t existed in the “before” variant (i.e. mount them)
- update items that existed “before” and continue to exist “after” (i.e. re-render them)
It’s much easier to understand when you play with code a little bit, so let’s do that as well.
Why random “key” attributes are a bad idea?
Let’s implement a list of countries first. We’ll have an Item component, that renders the country’s info:
const Item = ({ country }) => {return (<button className="country-item"><img src={country.flagUrl} />{country.name}</button>);};
and a CountriesList component that renders the actual list:
const CountriesList = ({ countries }) => {return (<div>{countries.map((country) => (<Item country={country} />))}</div>);};
Now, I don’t have the “key” attribute on my items at the moment. So what will happen when the CountriesList component re-renders?
- React will see that there is no “key” there and fall back to using the
countriesarray’s indexes as keys - our array hasn’t changed, so all items will be identified as “already existed”, and the items will be re-rendered
Essentially, it will be no different than adding key={index} to the Item explicitly
countries.map((country, index) => <Item country={country} key={index} />);
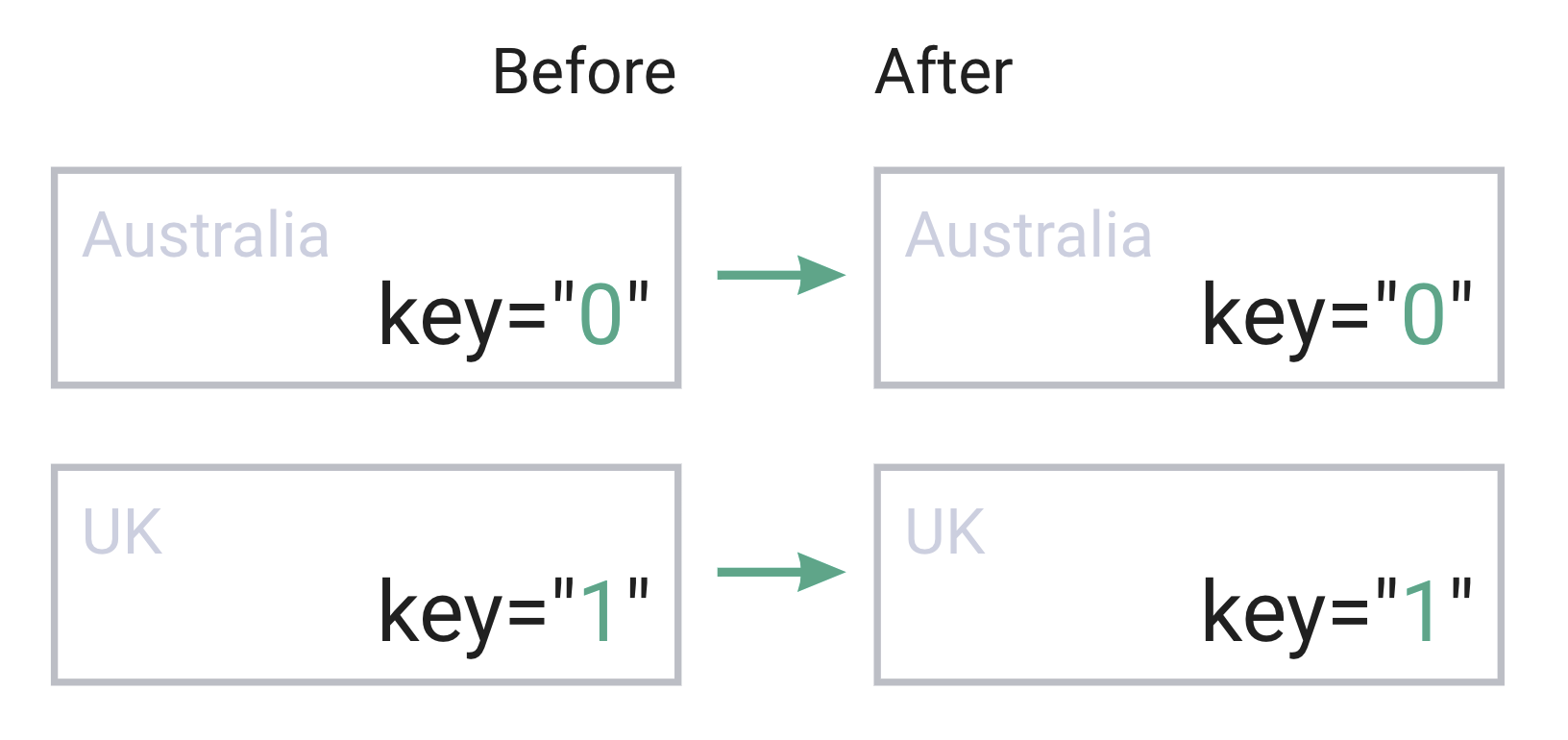
In short: when CountriesList component re-renders, every Item will re-render as well. And if we wrap Item in React.memo, we even can get rid of those unnecessary re-renders and improve the performance of our list component.
Now the fun part: what if, instead of indexes, we add some random strings to the “key” attribute?
countries.map((country, index) => <Item country={country} key={Math.random()} />);
In this case:
- on every re-render of
CountriesList, React will re-generate the “key” attributes - since the “key” attribute is present, React will use it as a way to identify “existing” elements
- since all “key” attributes will be new, all items “before” will be considered as “removed”, every
Itemwill be considered as “new”, and React will unmount all items and mount them back again
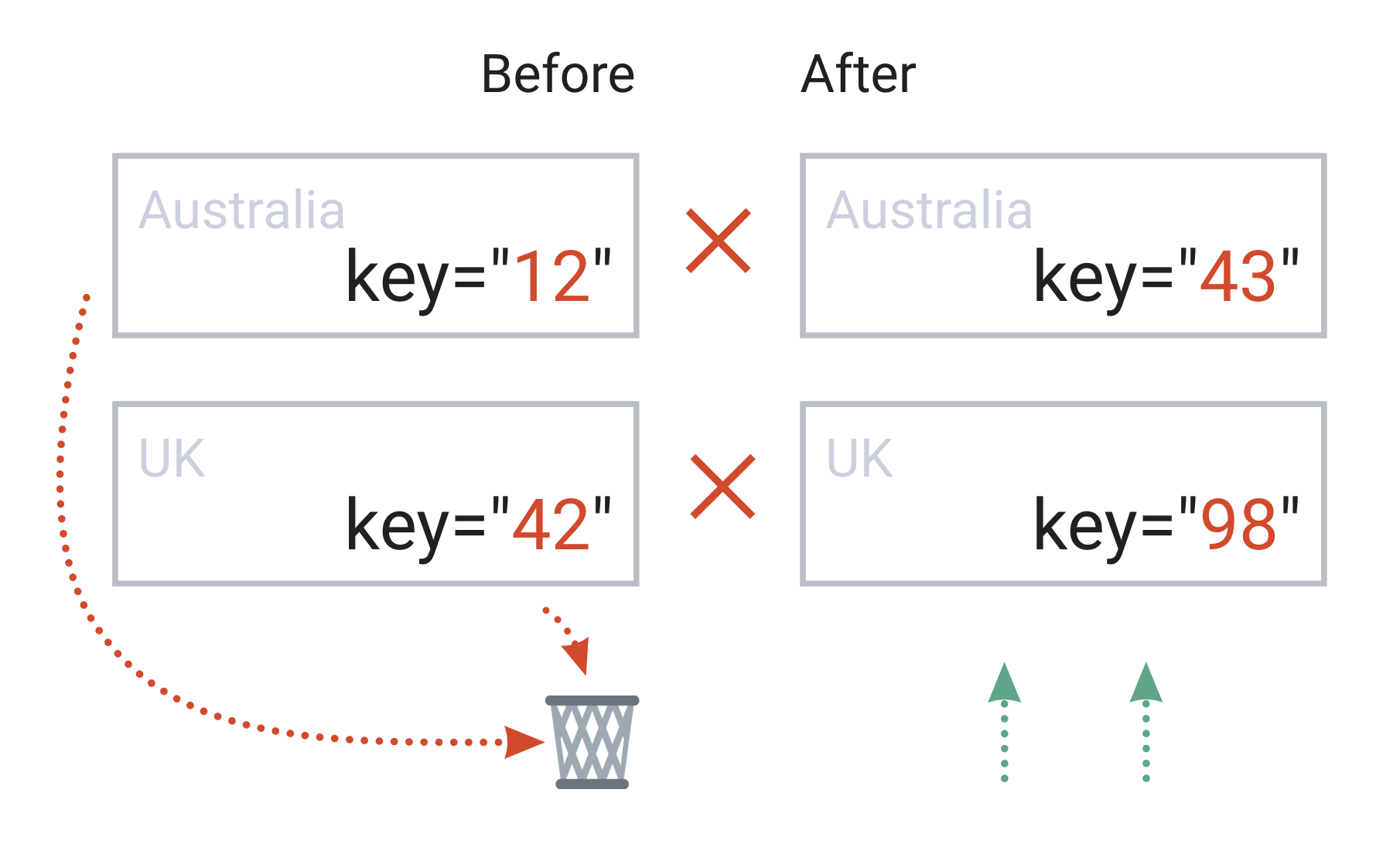
In short: when CountriesList component re-renders, every Item will be destroyed and re-created from scratch.
And re-mounting of components is much, much more expensive, compared to the simple re-render when we talk about performance. Also, all performance improvements from wrapping items in React.memo will go away - memoisation won’t work since items are re-created on every re-render.
Take a look at the above examples in the codesandbox. Click on buttons to re-render and pay attention to the console output. Throttle your CPU a little, and the delay when you click the button will be visible even with the naked eye!
How to throttle you CPUIn Chrome developer tools open “Performance” tab, click the “cogwheel” icon on the top right - it will open an additional panel, with “CPU throttling” as one of the options.
Why “index” as a “key” attribute is not a good idea
By now it should be obvious, why we need stable “key” attributes, that persist between re-renders. But what about array’s “index”? Even in the official docs, they are not recommended, with the reasoning that they can cause bugs and performance implications. But what exactly is happening that can cause such consequences when we’re using “index” instead of some unique id?
First of all, we won't see any of this in the example above. All those bugs and performance implications only happen in “dynamic” lists - lists, where the order or number of the items can change between re-renders. To imitate this, let’s implement sorting functionality for our list:
const CountriesList = ({ countries }) => {// introduce some stateconst [sort, setSort] = useState('asc');// sort countries base on state value with lodash orderBy functionconst sortedCountries = orderBy(countries, 'name', sort);// add button that toggles state between 'asc' and 'desc'const button = <button onClick={() => setSort(sort === 'asc' ? 'desc' : 'asc')}>toggle sorting: {sort}</button>;return (<div>{button}{sortedCountries.map((country) => (<ItemMemo country={country} />))}</div>);};
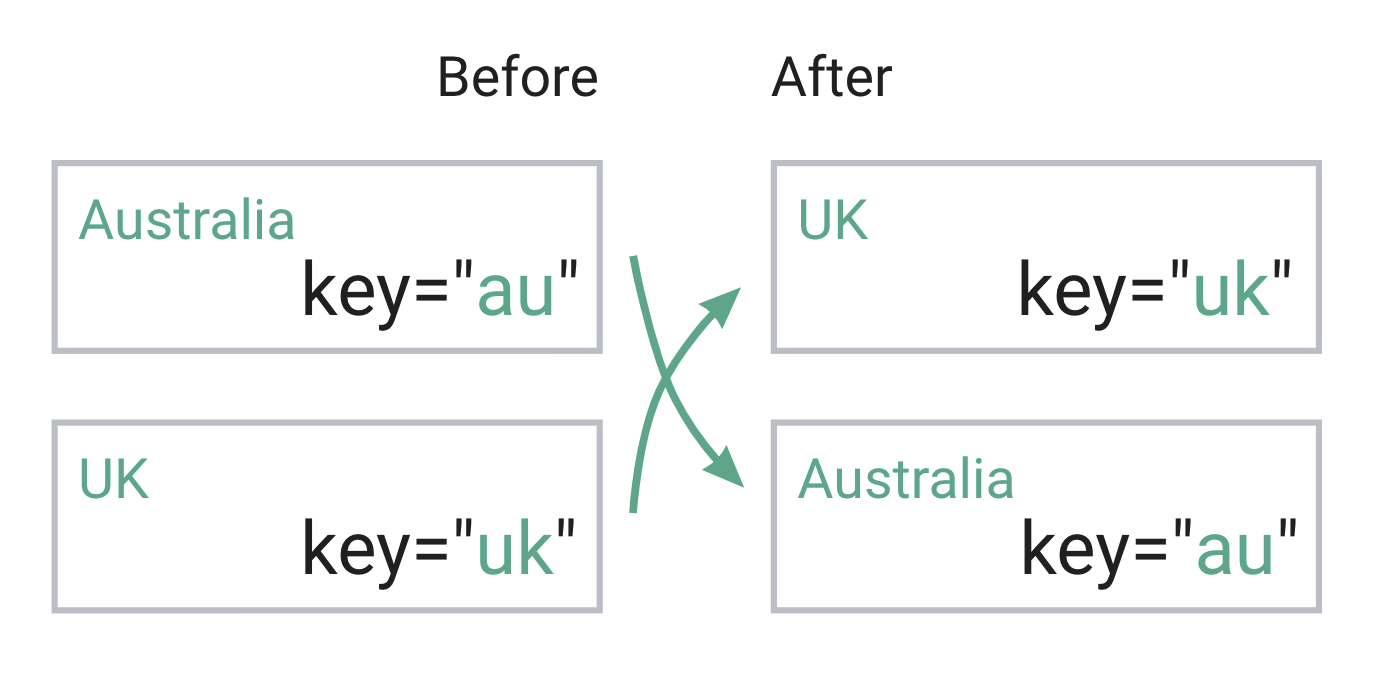
Every time I click the button the array’s order is reversed. And I’m going to implement the list in two variants, with country.id as a key:
sortedCountries.map((country) => <ItemMemo country={country} key={country.id} />);
and array’s index as a key:
sortedCountries.map((country, index) => <ItemMemo country={country} key={index} />);
And going to memoise Item component right away for performance purposes:
const ItemMemo = React.memo(Item);
Here is the codesandbox with the full implementation. Click on the sorting buttons with throttled CPU, notice how "index"-based list is slightly slower, and pay attention to the console output: in the "index"-based list every item re-renders on every button click, even though Item is memoised and technically shouldn’t do that. The "id"-based implementation, exactly the same as “key”-based except for the key value, doesn’t have this problem: no items are re-rendered after the button’s click, and the console output is clean.
Why is this happening? The secret is the “key” value of course:
- React generates “before” and “after” list of elements and tries to identify items that are “the same”
- from React’s perspective, the “same” items are the items that have the same keys
- in “index”-based implementation, the first item in the array will always have
key="0", the second one will havekey="1", etc, etc - regardless of the sorting of the array
So, when React does the comparison, when it sees the item with the key="0" in both “before” and “after” lists, it thinks that it’s exactly the same item, only with a different props value: country value has changed after we reversed the array. And therefore it does what it should do for the same item: triggers its re-render cycle. And since it thinks that the country prop value has changed, it will bypass the memo function, and trigger the actual item’s re-render.
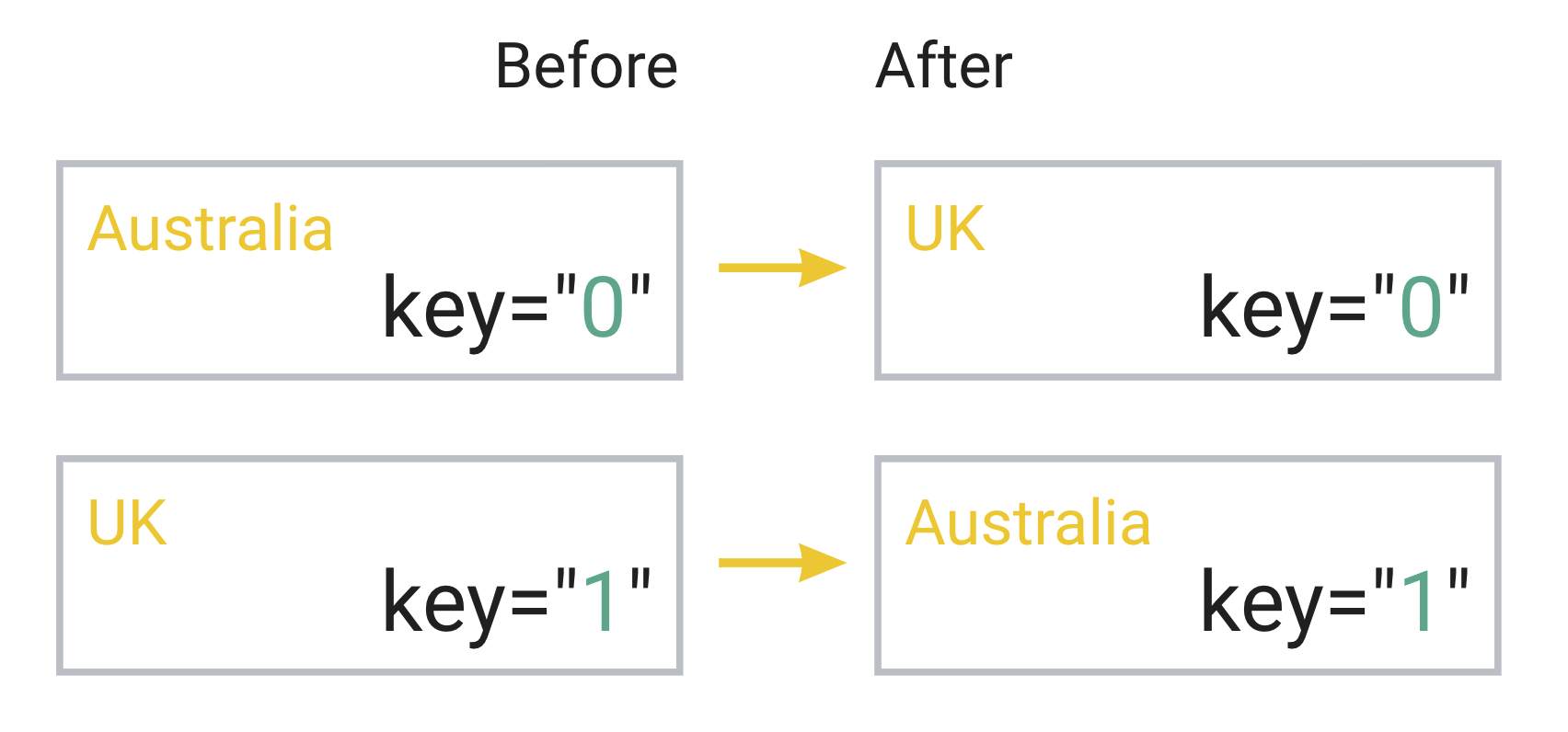
The id-based behaviour is correct and performant: items are recognized accurately, and every item is memoised, so no component is re-rendered.
This behaviour is going to be especially visible if we introduce some state to the Item component. Let’s, for example, change its background when it’s clicked:
const Item = ({ country }) => {// add some state to capture whether the item is active or notconst [isActive, setIsActive] = useState(false);// when the button is clicked - toggle the statereturn (<button className={`country-item ${isActive ? 'active' : ''}`} onClick={() => setIsActive(!isActive)}><img src={country.flagUrl} />{country.name}</button>);};
Take a look at the same codesandbox, only this time click on a few countries first, to trigger the background change, and only then click the “sort” button.
The id-based list behaves exactly as you’d expect. But the index-based list now behaves funny: if I click on the first item in the list, and then click sort - the first item stays selected, regardless of the sorting. And this is the symptom of the behaviour described above: React thinks that the item with key="0" (first item in the array) is exactly the same before and after the state change, so it re-uses the same component instance, keeps the state as it was (i.e. isActive set to true for this item), and just updates the props values (from the first country to the last country).
And exactly the same thing will happen, if instead of sorting we’ll add an item at the start of the array: React will think that the item with key="0" (first item) stays the same, and the last item is the new one. So if the first item is selected, in the index-based list the selection will stay at the first item, every item will re-render, and the “mount” even will be triggered for the last item. In the id-based list, only the newly added item will be mounted and rendered, the rest will sit there quietly. Check it out in the codesandbox. Throttle your CPU, and the delay of adding a new item in the index-based list is yet again visible with the naked eye! The id-based list is blazing fast even with the 6x CPU throttle.
Why “index” as a “key” attribute IS a good idea
After the previous sections it’s easy to say “just always use a unique item id for “key” attribute”, isn’t it? And for most cases it’s true and if you use id all the time nobody will probably notice or mind. But when you have the knowledge, you have superpowers. Now, since we know what exactly is happening when React renders lists, we can cheat and make some lists even faster with index instead of id.
A typical scenario: paginated list. You have a limited number of items in a list, you click on a button - and you want to show different items of the same type in the same size list. If you go with key="id" approach, then every time you change the page you’ll load completely new set of items with completely different ids. Which means React won’t be able to find any “existing” items, unmount the entire list, and mount completely fresh set of items. But! If you go with key="index" approach, React will think that all the items on the new “page” already existed, and will just update those items with the fresh data, leaving the actual components mounted. This is going to be visibly faster even on relatively small data sets, if item components are complicated.
Take a look at this example in the codesandbox. Pay attention to the console output - when you switch pages in the “id"-based list on the right, every item is re-mounted. But in “index"-based list on the left items are only re-rendered. Much faster! With throttled CPU, even with 50 items very simple list (just a text and an image), the difference between switching pages in the “id"-based list and “index"-based list is already visible.
And exactly the same situation is going to be with all sorts of dynamic list-like data, where you replace your existing items with the new data set while preserving the list-like appearance: autocomplete components, google-like search pages, paginated tables. Just would need to be mindful about introducing state in those items: they would have to be either stateless, or state should be synced with props.
All the keys are in the right places!
That is all for today! Hope you liked the read and have a better understanding now of how React “key” attribute works, how to use it correctly, and even how to bend its rules to your will and cheat your way through the performance game.
A few key takeaways to leave with:
- never use random value in the “key” attribute: it will cause the item to re-mount on every render. Unless of course, this is your intention
- there is no harm in using the array’s index as “key” in “static” lists - those whose items number and order stay the same
- use item unique identifier (“id”) as “key” when the list can be re-sorted or items can be added in random places
- you can use the array’s index as “key” for dynamic lists with stateless items, where items are replaced with the new ones - paginated lists, search and autocomplete results and the like. This will improve the list’s performance.
Have a great day, and may your list items never re-render unless you explicitly told them so! ✌🏼
Also, check out the YouTube video that explains content of the article using some pretty animations: